The Data Window
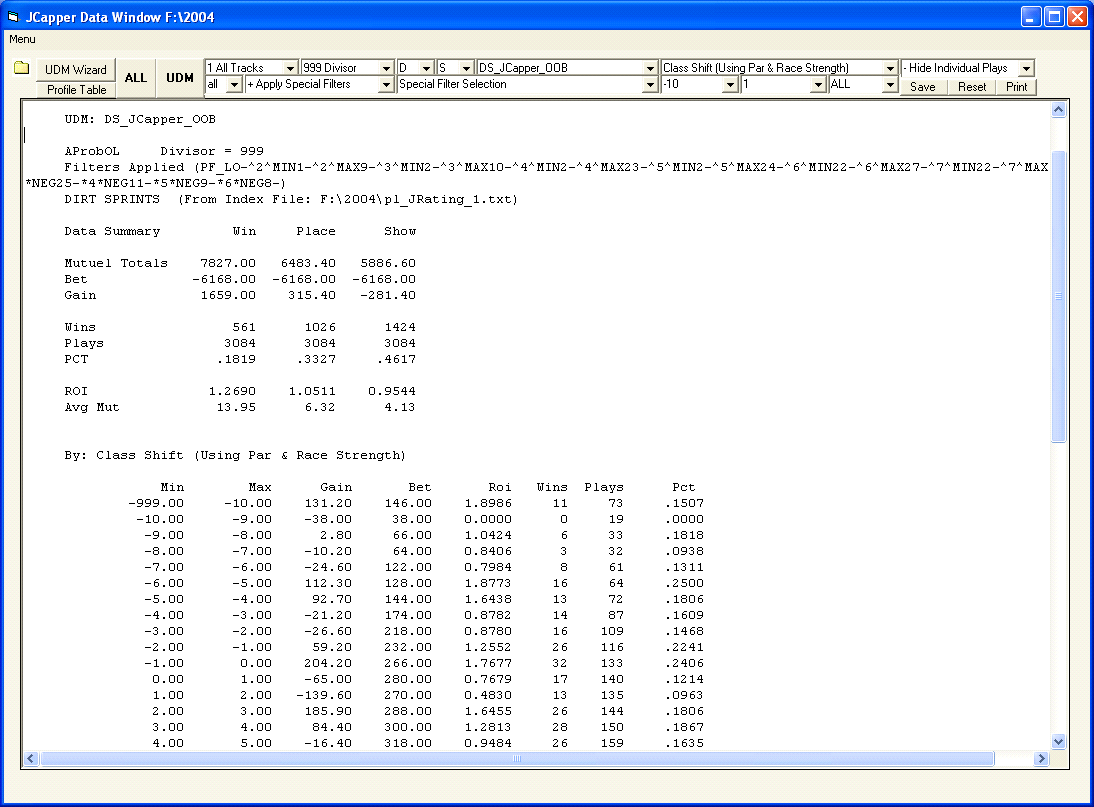 Screenshot above: The JCapper Data Window shown in
1280 X 1024 Screen Resolution
Screenshot above: The JCapper Data Window shown in
1280 X 1024 Screen ResolutionGeneral
Overview
The Data Window was designed to provide an interface
enabling the JCapper user to perform his or her own research, querying a
JCapper database to discover the performance of any single factor, or
combination of factors, supported by JCapper. The Data Window was designed so
that it can be used by those who know absolutely nothing about programming.
Individual factors may be included as part of a query simply by selecting them
from Drop Downs. Queries involving combinations of factors may involve a
learning curve, but rest assured, every possible
combination of supported factors found in a JCapper Database can be tested
using the Data Window.
Screen
Resolution/Auto Resize
The Data Window contains logic that enables it to
detect the user's screen resolution and size itself accordingly. Shown above in
1280 x 1024 there are two rows of drop downs. When rendered in lower screen
resolutions, three rows of drop downs are used and the Data Window is resized
so that all of it may be displayed on the smaller screen real estate that is
available.
Note - Manual
Resize - On
some machines, notably those with AMD K-6 microprocessors, Windows may be
unable to interface properly with the graphics card. As a result, Windows will
not have access to screen resolution when the Data Window is started, and auto
sizing of the Data Window at startup will be impacted. If you are unable to
view the complete Data Window screen area, this is the cause. For those users
whose machines have AMD K-6 processors, I have added a Resize menu option.
Click Menu and select Resize. The Data Window will resize itself as if it were
operating in an 800 x 600 screen resolution environment. This should allow all
users to view the entire Data Window screen area. If the Resize menu item is
clicked a second time, the Data Window will size itself according to whatever
screen resolution information is currently stored in Windows.
Mouse Over Tool Text
Every Visible Element found on the Data Window
responds to a mouse over event and provides Tool Text whenever the mouse cursor
is positioned above the element. Or, in layman's terms, if you want to know
what a drop down or button does, simply position the mouse cursor on top of it
and a yellow Tool Text pop up will appear containing a brief description of
what it is that the element does.
Visible
Elements
Each Visible Element on the Data Window serves a
purpose. Each can, in some way, help the user to create a query. What follows
is a section for each element along with a description of what it does and how
to use it.
Folder Icon
The Folder Icon provides a way for the user to
navigate to other folders on the system. When the Data Window first loads, it
points at the Default Data Folder. The current folder being pointed to is always displayed on the blue Data Window Title Bar located
at the top of the Data Window screen. To change the pointed to folder, simply
click on the Folder Icon. A set of Folder Navigation Tools will appear.
Navigate to (or point the Data Window to) a different folder simply by double
clicking on a folder name displayed by the Folder Navigation Tool. Each time a
new current folder is selected, the new folder name will appear on the Title
Bar. Hint~ You
always want to fist point the Data Window to the folder where the JCapper
Database that you wish to query resides.
ALL Button
Use the ALL button to run queries against all horses
found in the database. After clicking the ALL button, a dialog box will appear.
The current folder is displayed in the Look In text box of the dialog.
Available PlayList and Quick Index Files are shown in the larger white box of
the dialog. The default PlayList file (PL_Profile.txt) is displayed in the file
name box of the dialog. To open this index file and use it to run the query,
simply click the Open button. Or, to select a different index file, simply
click on the file name of the desired index file and then click the Open
button. If no PlayList or index files are displayed in the large box, this
means that the Data Window is pointed to a folder that does not contain any
PlayList or index files or that no JCapper database has yet been created. Point
the Data Window to a folder containing a JCapper Database or use the Database
Builder to create one.
UDM Button
Use the UDM button to run a UDM as a query against
the database. Select the UDM you want to use from the UDM drop down first. Then
click the UDM button. After clicking the UDM button, a dialog box will appear.
The current folder is displayed in the Look In text box of the dialog.
Available PlayList and Index Files are shown in the larger white box of the
dialog. The default PlayList file (PL_Profile.txt) is displayed in the file
name box of the dialog. To open this index file and use it to run the query,
simply click the Open button. Or, to select a different index file, simply click
on the file name of the desired index file and then click the Open button. If
no PlayList or index files are displayed in the large box,
that means that the Data Window is pointed to a folder that does not
contain any PlayList or index files or that no JCapper database has yet been
created. Point the Data Window to a folder containing a JCapper Database or use
the Database Builder to create one.
UDM Drop Down
The UDM Drop Down can be used to specify the UDM to
be used for the query. Only the UDM button responds to selections made using
the UDM drop down. To run a UDM as a query, select the desired UDM from the UDM
drop down and click the UDM button. If you want any Filters that are part of
the UDM Definition of the selected UDM to be included in your query, select
Apply Special Filters from the Filters drop down.
Other Query
Elements
The other visible elements on the Data Window may be
used to refine the parameters of a query. Both the ALL button and the UDM
button respond to selections made using the Other Query Elements. A section for
each element and a description of how to use it follows below.
Select Track
Drop Down
The Select Track Drop Down can be used to query the
database for races run at a specific track only. The default position for this
drop down is ALL tracks. To create a query restricted to a single track, simply
select “Select Track” using the Select Track drop down. When Select Track is
selected, you will be prompted for the Bris Track File Code after clicking
either the ALL or UDM buttons. Simply enter the track code characters (first
three letters of the Bris data file) at this prompt to restrict your query for
that particular track.
Divisor Drop
Down
The Divisor Drop Down can be used to define minimum
playable odds for your query. A Divisor in JCapper is a number used to divide
the field size by in order to obtain minimum odds. For example, if field size
is 12 and selected Divisor is 1.5, then minimum odds for the query would be
8-1. The default for this drop down is 999. That means that minimum odds are
field size divided by 999 or effectively no minimum odds restriction.
Options available with this drop down are:
Selection Minimum
Odds
999 Field
Size divided by 999
5 Field
Size divided by 5
2.5 Field
Size divided by 2.5
1.5 Field
Size divided by 1.5
1.2 Field
Size divided by 1.2
0.7 Field
Size divided by 0.7
AProbOL Assigned
Probability Odds Line
AProbOL x 1.5 Assigned
Probability Odds Line multiplied by 1.5
PScoreOL PScore
Odds Line
3-1 Min Odds 3-1
6-1 Min Odds 6-1
9-1 Min Odds 9-1
Surface Drop
Down
The Surface Drop Down can be used to define a
running surface for the query.
Options available with this drop down are:
Selection Surface
D* All
Dirt Courses
D Main/Outer
Dirt Course Only
d Inner Dirt Course Only
T* All
Turf Courses
T Main/Outer
Turf Course Only
t Inner Turf Course Only
O Off
the Turf
* All
Courses - Dirt, Turf, or Off the Turf
Note about PolyTrack: In JCapper I have decided for the time being not to use a separate
surface to describe PolyTrack. Users have the ability to write UDMs and make
ImpactValue table entries to require and avoid specific tracks. At the time of
this writing the following tracks are running races on artificial surfaces:
APX-DMR-HOL-KEE-PID-TPX-WOX. Users wanting to enforce decisions to either
require or avoid artificial surfaces can do so by using these (and future)
track codes in combination with a surface designation of D*.
Distance Drop
Down
The Distance Drop Down can be used to define a general
distance category for the query.
Options available with this drop down are:
Selection Distance
Category
S Sprint
(less than 8.0 furlongs)
* All
Distances - Sprint or Route
Numeric Specifies
exact distance in furlongs from 1.0f to 16.0f
Factors Drop
Down
The
Factors Drop Down can be used to select a Factor. Any time a factor is selected
using the Factors Drop
Down, a separate section appears in the query results with
a distribution for the factor selected. All of the supported factors found in
JCapper can be found in the Factors Drop Down.
Where available, selections can be made for a factor by rank for that factor,
gap relative to
the rest of the field, or numeric value for that factor. The factors drop down responds
to keystrokes. For example, to find JRating as a factor alphabetically, open
the Factors drop down and hit the "J" key on the keyboard. The drop
down will jump to those factors that begin with the letter J.
Key Factors
Report
The Key Factors Report is a new feature added to the
Data Window in late October 2008. When KEY FACTORS REPORT is selected from the
Data Window’s Factors Drop Down, the next Data Window query run by the user drives
the Key Factors Report. This causes the Data Window to show results for the next Data Window query run broken
out by rank = 1 for approximately 60 plus JCapper factors in three separate
sections. The first section is sorted by Factor Name. The second section is sorted
by Impact Value for win percent. And the third section is sorted by flat Win
Bet ROI. Needless to say user feedback for this new feature has been
overwhelmingly positive. JCapper users everywhere keep telling me they
absolutely love this new feature and find it to be a great timesaver.
Data Window
Exports
If you click MENU and then select Exports, you will
notice a number of Data Window Exports that can be run. These are covered in a
separate Help Doc. I have also produced and published a Data Window Exports video.
For details on how to run Data Window Exports I recommend that you read the
Data Window Exports help Doc and watch the video(s). As of this writing the
following Data Window Exports are available:
- Comprehensive Reports for Trainers, Riders and Owners.
- Track Profile Reports
- Key Factors Report
Data Window Exports are designed to provide a way of
letting you see your data in a way that helps you create viable UDMs in the
shortest amount of time possible. Want to know who the overlooked trainers are
on your favorite circuit? Run a Data Window Export for Trainers and then
generate an Overlooked Trainers Report. Watch the video. You’ll be blown away
by what’s on the report and how easy it is to actually see who is good and bad
at what.
The
Interval Drop
Down
The Interval drop down can be used to define the
interval between min and max values for the data displayed by a factor
distribution. Whenever a factor is selected from the factors drop down, the
Interval drop down is re-set to the default display interval for that factor.
To override the default, select a new interval after selecting a factor.
Individual
Plays Drop Down
The Individual Plays drop down can be used to
display the individual plays returned by the query. To display the individual
plays, simply select + Show Individual Plays from the
drop down. To hide individual plays, select the default setting - Hide
Individual Plays from the drop down.
Class
Descriptor Drop Down
The Class Descriptor drop down can be used to define
a class descriptor for the query. Whenever a class descriptor has been defined,
the query will only contain results for the races that match the class
descriptor selected.
Options available with this drop down are:
Selection Class
Descriptor
ALL All
Class Descriptors
C Claiming
CO Claiming
Optional
M Maiden
Claiming
S Maiden
Special Weight or Straight Maiden
A Allowance
G Graded
Stakes
N Non
Graded Stakes
R Starter
Allowance
T Overnight
Handicap
Special
Filters Drop Down
The Special Filters Drop Down is used to invoke
application of preset or dynamic filters as part of the query.
Options available with this drop down are:
No Special
Filters -
Preset or Dynamic Filters are NOT included in query results.
+ Apply
Special Filters - Preset or Dynamic Filters ARE included in query results.
~ Horses
Filtered Out
- Query results only contain those horses filtered out by selected preset or
dynamic filters.
When the ALL button is clicked, the Special Filters
drop down works in conjunction with the Special Filter Selection drop down. To
apply a preset filter to the query with the ALL button, select + Apply Special Filters and select the desired filter from the
Special Filter Selection drop down. Both must be present for the filter to be
applied as part of the query.
When the UDM button is clicked with either + Apply
Special Filters or ~
Horses Filtered Out selected from the Special Filters Drop Down, any filter codes
that are part of the UDM Definition for the UDM being run become part of the
query. If - No Special Filters is selected from the Special Filters Drop Down
when the UDM button is clicked, any filter codes that are part of the UDM
Definition for the UDM being run do not
become part of the query.
Special Filter
Selection Drop Down
The Special Filter Selection Drop Down can be used
by the user to select any of the Preset Filters supported by JCapper. The
Special Filter Selection Drop Down works in conjunction with the Special
Filters drop down as described above.
Special Filter
Selection Drop Down- Keying in a Dynamic Filter
The Special Filter Selection drop down also doubles
as a text box. Dynamic Filters can be declared in the drop down simply by typing
in valid filter codes. Of course, before the filter is included as part of the
query, either + Apply Special Filters or ~ Horses Filtered Out must be selected
from the Special Filters drop down when either the ALL or UDM buttons are
clicked.
When valid dynamic filter codes are typed into the
Special Filter Selection Drop Down, and either + Apply Special Filters or ~
Horses Filtered Out have been selected from the Special Filters drop down and
the UDM button is clicked, and the UDM being run already has filter codes as
part of its UDM Definition, then the parameters for the query will include both the filter codes from the UDM and
the filter code(s) typed into the Special Filter Selection Drop Down.
Special Filter
Selection Drop Down- Query by Trainer Name
The Special Filter Selection Drop Down can also be
used to create a query for a specific trainer name. To query by trainer name,
select Trainer Name (Prompt w/ALL or UDM buttons) from the Special Filter
Selection Drop Down. After doing so, whenever the ALL or UDM buttons are
clicked, you will be prompted for a trainer name. The query will then contain
results only for those horses where a trainer name match exists between the
trainer name in the database and the trainer name keyed in at the prompt. It is
not necessary for + Apply Special Filters or ~ Horses Filtered Out to be
selected when querying by trainer name.
Special Filter
Selection Drop Down- Query by Rider Name
The Special Filter Selection Drop Down can also be
used to create a query for a specific rider name. To query by trainer name,
select Rider Name (Prompt w/ALL or UDM buttons) from the Special Filter
Selection Drop Down. After doing so, whenever the ALL or UDM buttons are
clicked, you will be prompted for a rider name. The query will then contain
results only for those horses where a rider name match exists between the rider
name in the database and the rider name keyed in at the prompt. It is not necessary for + Apply Special
Filters or ~ Horses Filtered Out to be selected when querying by rider name.
Special Filter
Selection Drop Down- Query by
The Special Filter Selection Drop Down can also be
used to create a query for a specific date range. To query by date range,
select
Special Filter
Selection Drop Down- Query by Sire Name
The Special Filter Selection Drop Down can also be
used to create a query for a specific sire name. To query by sire name, select
Sire Name (Prompt w/ALL or UDM buttons) from the Special Filter Selection Drop
Down. After doing so, whenever the ALL or UDM buttons are clicked, you will be
prompted for a sire name. The query will then contain results only for those
horses where a sire name match exists between the sire name in the database and
the sire name keyed in at the prompt.
.
Shippers Drop
Down
The Shippers drop down can be used to define the
status of horses shipping in from other tracks as part of the query.
Options available with this drop down are:
Selection Description
ALL Shippers
are irrelevant to the query
1 Non Shipper Only
non shippers are included in the query results
2 Shipper Only
shippers are included in the query results
Save Button
The Save button can be used to save the displayed
query results to a text file in the current or pointed to folder. When the Save
button is clicked a dialog box will appear showing the path and file name of
the file to be saved. the default file name is Impact_Study.txt.
Users have complete ability to change the file and/or path name before saving.
Print Button
The Print button can be used to send the displayed
query results to any printer on the user's system. When the Print button is
clicked, a print dialog box will appear showing available printers. Refer to
your Windows Printer Setup documentation for more information on setting up
printers.
Reset Button
Clicking the Reset button resets all visible
elements to their default positions. In addition, clicking the Reset Button
causes re-population of the UDM drop down from the Profile Table.
UDM Wizard
Button
Clicking the UDM Wizard Button on the Data Window
launches the UDM Wizard right from the Data Window. This allows users to create
or modify UDMs, save them, hit the Data Window Reset Button, and then
immediately test out the UDM just created or modified in the Data Window. This
is a great way to test out new ideas or tweak existing UDMs. Using the Data
Window in conjunction with the UDM Wizard enables the user to test out any and
all combinations of factors found in the UDM Wizard..
Profile Table
Interface Button
Clicking the Profile Table Interface Button on the
Data Window launches the Profile Table Interface right from the Data Window.
This allows users to create or modify UDMs, save them, hit the Data Window
Reset Button, and then immediately test out the UDM just created or modified in
the Data Window. This is a great way to test out new ideas or tweak existing
UDMs. Using the Data Window in conjunction with the Profile Table Interface
enables the user to test out any and all combinations of factors supported by
JCapper.
-End of section
covering visual Data Window Elements-
PlayList Files
– Prerequisite for Running Queries in the Data Window
In JCapper, the data source for all Data Window
Queries comes from PlayList Files.
PlayList files are comma delimited text files
created by the Database Builder. PlayList files all have a common file naming schema
- the letters PL followed by an underscore character _ followed by some text
description followed by the file extension .txt. For example, the file named
PL_Profile.txt is the standard file name for the PlayList file created by the
Database Builder whenever a Build Database routine is run.
Many new
users make the assumption that just because they have copied past performance
and results files onto a folder and unzipped them that the program can somehow
now magically use them. Not so. You first have to first run a Build Database on
a target folder that contains both unzipped past performance data files and
unzipped XRD results files before you will have a PlayList File on the target
folder. During a Build Database routine the Database Builder will, among other
things, match up your past performance and XRD results files by track and date
and create a PlayList file named PL_Profile.txt on the target folder. It is
this PlayList file that acts as the data source. It contains the data needed by
the Data Window to run queries.
Quick Index
Files
Quick Index Files are a special category of PlayList
Files. Quick Index Files behave the same way as regular PlayList Files. You can
open them in the Data Window to run Data Window Queries. Quick Index Files are
different from regular PlayList Files in that Quick Index Files are smaller
because they contain only a limited number of starters usually sharing a
special characteristic like top rank for a given factor. Data Window Queries
run using Quick Index Files run noticeably
faster than queries run using standard PlayList files. The section devoted
to the Quick Index File Extract Tool presented later on in this Help Document
provides a complete discussion on creating quick index files.
Starter
Database Files
Starter Database Files are another special category
of PlayList files. Starter Database Files behave the same way as regular
PlayList Files. Starter Database Files are different from regular PlayList
Files in that proprietary info belonging to Bris, such as Bris Speed Figures,
Bris Pace Figures, and Bris Prime Power are not found in them. But you can open
them in the Data Window to run Data Window Queries based on rank and gap for
Bris factors. You can also use them to run Data Window Queries for any and all
of the unique numbers created by JCapper such as JRating, CPace, PMI, OP, Form,
WoBrill, etc.
Step by Step:
How to Run Basic Data Window Queries
Below I’ll present the basic steps to follow in
order to run simple queries with the Data Window. Simple Data Window Queries
always begin with the user clicking the ALL Button. Query parameters are
determined by user selections of factors and filters using the Data Window’s
drop downs. Results returned is data that is read from the user selected
PlayList file in the dialog box that appears after clicking the ALL Button.
1. Open the
Data Window
- From the Main Module, click the Data Window Button. This will cause the Data
Window to open. You should see your Default Data Folder c:\2006 displayed
across the blue Title Bar at the top of the Data Window. If you are using a
different Default Data Folder, click the Data Window's Folder Icon, use the
Folder Nav Tool to navigate through the folder structure on the current drive,
and select your target folder by double clicking it. When you see your target
folder displayed across the blue Title Bar at the top of the Data Window, close
the Folder Nav Tool by clicking anywhere on the Data Window outside of the
Folder Nav Tool.
2. Select a
Breakout Factor from the Factors Drop Down – Suppose you want to run a simple Data
Window query for JRating Rank. Select JRating Rank as your breakout factor from
the Factors Drop Down.
3. Select
Surface and Distance – Suppose you want to see query results for all surfaces and all
distances. Select * for surface and * for distance. This means that we will be
running a query broken out by JRating Rank for horses that ran on any surface
at any distance in the selected PlayList file.
Select Other
Optional Factors
Optionally, at this point, you could select
parameters from other drop downs as well. For example, if you wanted your query
to be for Graded Stakes Races only you could select G from the Class Descriptor
Drop Down. If you wanted to add the further requirement that query results only
be for horses that went to post at 6-1 or higher you could select 6-1 Min Odds
from the Divisor Drop Down.
4. Click the
ALL button.
This will open a file selection dialog box. If any PlayList files are present
on the target folder their file names will be displayed inside of this dialog
box. If you see no file names for PlayList Files in the dialog box then that
means that the folder you currently have the Data Window pointed to does not
have any PlayList files on it. If that is the case, click the CANCEL button and
go back to Step 1 above. Use the Folder Nav Tool to point the Data Window at a
folder that actually has a PlayList File on it before continuing. If you do not
yet have any PlayList Files present on your system, click CANCEL and READ the
section above in this Help Document titled PlayList
Files – Prerequisite for Running Queries in the Data Window.
5. Select a
PlayList file - Single click a PlayList File name. For example, find the PlayList file
named PL_Profile.txt and give it a single click.
6. Click the
OPEN button
on the file selection dialog box. The Data Window will begin running its query.
This could take anywhere from a second or two to several minutes depending on
the size of the PlayList File being used as the data source. While the query is
being run the Data Window output screen will flash a message "Querying
Database Please Stand By..."
After the all data has been read from the PlayList
File results information is then displayed in the Data Window output screen.
The top section of queries run using the ALL button
shows a breakout for ALL horses in the query by WIN, PLACE, and SHOW.
The next section shows a breakout by the selected
factor - in this case JRating Rank. The horizontal line for Rank 1 shows what
happened had a flat $2.00 win bet been made on every top ranked JRating horse
in the query. The line for Rank 2 shows the same thing for the second ranked
horse... and so on... all the way through the top 19 positions.
The next section shows a breakout by odds range for
all horses in the query.
The final section at the bottom shows a bankroll
summary for all horses in the query - starting with a mythical bank of $2500.00
and betting 2.5 percent of bankroll on each horse in the query.
That's a very basic query- all horses in the
database broken out by a single factor. Don’t be afraid to play around with it
a little: Experiment. Run many different queries using different single factors
at various surfaces and distances. Play around with the drop downs. Run a few
different queries at individual tracks and class descriptors. The basic idea is
to become familiar with the Data Window layout before moving on to more
advanced queries.
Complex Data
Window Queries
Below I’ll present the basic steps to follow in
order to run complex queries with the Data Window. Complex Data Window Queries
always begin with the user clicking the UDM Button. Unlike simple Data Window
Queries that are run from the ALL Button, Complex Data Window Query parameters
are determined by the UDM Definition
stored in the Profile Table. When the
UDM Button is clicked you’ll notice that many of the Data Window drop downs
will automatically change to # UDM Def. Visually, this is my way as the
programmer of telling the user that the results displayed as a result of your
query are based on whatever parameters are found in the UDM Definition. By
controlling the UDM Definition it is possible to define the parameters of your
query. If you so choose, you can set your UDM Definition to include: a min and
max value, a min and max rank, and a min and max gap for every single factor
that has a corresponding field in the Profile Table. In addition, a UDM
Definition may contain any of the several hundred Preset Filer Codes or any and
all possible combinations of Dynamic Filter Codes. Once that has been
accomplished, simply by clicking the UDM Button, you can then run that UDM
through the Data Window as a Complex Data Window Query. This will enable you to
see how all horses in your PlayList file with an exact fit for a given UDM
Definition would have performed in terms of win rate and win ROI. Further, you
can do this with an individual factor selected from the Factors Drop Down. This
enables you to very clearly see what effect if any changing your UDM Definition
might have had. The amount of power and flexibility in this feature is
enormous. Once creating UDMs with the UDM Wizard and Profile Table Interface is
understood, the user is limited only by his or her imagination as to what
factor combinations can be checked out and subsequently used in a UDM
Definition.
Running a UDM
through the Data Window – Step by Step
1. Open the
Data Window
- From the Main Module, click the Data Window Button. This will cause the Data
Window to open. You should see your Default Data Folder c:\2006 displayed
across the blue Title Bar at the top of the Data Window. If you are using a
different Default Data Folder, click the Data Window's Folder Icon, use the
Folder Nav Tool to navigate through the folder structure on the current drive,
and select your target folder by double clicking it. When you see your target
folder displayed across the blue Title Bar at the top of the Data Window, close
the Folder Nav Tool by clicking anywhere on the Data Window outside of the
Folder Nav Tool.
2. Select a
Breakout Factor from the Factors Drop Down – Suppose you want to run your UDM broken
out by CPace Rank. Select CPace Rank as your breakout factor from the Factors
Drop Down.
3. Select a
UDM –
Select the UDM you want to run as a complex query from the UDM Drop Down.
4. Click the
UDM button.
This will open a file selection dialog box. If any PlayList files are present
on the target folder their file names will be displayed inside of this dialog
box. If you see no file names for PlayList Files in the dialog box then that
means that the folder you currently have the Data Window pointed to does not
have any PlayList files on it. If that is the case, click the CANCEL button and
go back to Step 1 above. Use the Folder Nav Tool to point the Data Window at a folder
that actually has a PlayList File on it before continuing. If you do not yet
have any PlayList Files present on your system, click CANCEL and READ the
section above in this Help Document titled PlayList
Files – Prerequisite for Running Queries in the Data Window.
5. Select a
PlayList file - Single click a PlayList File name. For example, find the PlayList file
named PL_Profile.txt and give it a single click.
6. Click the
OPEN button
on the file selection dialog box. The Data Window will begin running its query.
This could take anywhere from a second or two to several minutes depending on
the size of the PlayList File being used as the data source. While the query is
being run the Data Window output screen will flash a message "Querying
Database Please Stand By..."
After all the data has been read from the PlayList
File, results information is then displayed in the Data Window output screen.
The very top section shows the parameters upon which
the query was based. In this case those parameters are the UDM Definition as it
exists in the Profile Table.
The next section shows a breakout for all horses in
the query by WIN, PLACE, and SHOW.
The next section shows a breakout by the selected
factor - in this case CPace Rank. The horizontal line for Rank 1 shows what
happened had a flat $2.00 win bet been made on every top ranked CPace horse
that fit the exact UDM Definition upon which the query was based. The line for
Rank 2 shows the same thing for the second ranked horse... and so on... all the
way through the top 19 positions.
The next section shows a breakout by odds range for
all horses in the query.
The final section at the bottom shows a bankroll
summary for all horses in the query - starting with a mythical bank of $2500.00
and betting 2.5 percent of bankroll on each horse in the query. Note: Starting with JCapper2007, users have
the ability to use the System Definitions Screen to define parameters for
starting bank, percentage of bankroll for each bet, and max bet size and see
those user definitions for money management applied by the Data Window to all
queries run through it.
Those are the steps for running a UDM through the
Data Window. Don’t be afraid to play around with it a little: Experiment. Use
the UDM Wizard to create a handful of your own UDMs. They don’t have to be
effective at first. The important thing at first is to learn how the software
works. You have to learn to crawl before you can walk. You must learn to walk before
you can run. Before you can create UDMs that are profitable going forward, you
need to learn how to use the software to create simple UDM Definitions. Focus
merely on adding a constraint for factor rank for a selected factor to a UDM
Definition. If you spend enough time with it you will eventually learn how to
fly. But understand that if you try to jump off a cliff after using the
software for only a very short time, when you flap your wings, you are going to
fall to the ground and go thump. So set up many different UDMs using different
single factors at various surfaces and distances. Perform your own research.
Run your UDMs back through the Data Window and see the win rate and win ROI for
factor combinations that interest you. Above all understand that you will LEARN
about the game at the same time you are learning how to use the software.
Important Note
about Odds Line display on the Reports and in the Data Window
Odds Line Type
Displayed on the Reports - In the original JCapper there was only one odds line: AProbOL. In
the summer of 2005 I added the PScoreOL and gave users a choice of which Odds
Line to display on the reports. In JCapper2007 users have two additional
choices: JPRMLOL and UPRMLOL (or User Defined Odds Line.) There is only so much
room on the HTML Report. The program has hundreds of factors and I can’t
possibly fit all of them on the HTML Report. For that reason, you the user,
have a responsibility. You have to go into the System Settings/System
Definitions Screen and choose the single odds line type that best fits your own
UDMs. The Odds Line that you select and save on the System Definitions Screen
is the odds line that you’ll see displayed on your reports.
Default Odds Line Type for UDMs in the Data Window –When you check the OL Test
checkbox for a UDM in the UDM Wizard you are adding a requirement to the UDM
Definition that the UDM only select horses that go off at odds greater than or
equal to the odds expressed by the odds
line. Sounds easy so far, right? But hold on a second. Which odds line? You
have several choices, remember? There is a rule covering this and here it is:
The same Odds Line that you select and save on the System Definitions Screen
that drives the odds line you see displayed on your reports is the same odds
line used as a default by the Data Window when you run your UDMs through the
Data Window.
So if you have JPRMLOL saved in System Definitions
you will see the JPRMLOL (also called JPRMLProbOL) on your reports. If you have
a UDM where you have checked the OL Test box and you run that UDM through the
Data Window using the UDM button – the Data Window will evaluate each horse in
the database and make a comparison between post time odds and the odds
expressed by the JPRMLOL when it determines whether or not that horse should be
returned as part of your query results.
Use the System Definitions Screen to change to a
different Odds Line type and your new Odds Line type will drive what you see on
the reports and in the Data Window.
-end
section on Data Window-
Quick Index File Extract Tool
The Quick Index File Extract Tool can be accessed by
clicking the Quick Index File Extract
button found on the JCapper Main Module or the QX button found on the Data Window. You can use the Quick Index
File Extract tool to extract a Quick Index File from any of your PlayList
files. A Quick Index File is identical to a PlayList file, but contains only
those starters in it that match the parameters selected by the user at build
time. The Quick Index File Extract tool allows users to build Index Files by
various combinations of both factor and rank. Index Files can be built that
contain only the starters from an individual trainer, only those starters from
an individual track, and only those starters where rank equals a selected value
for a selected factor. An Index File created where JRating Rank = 1 will only
have those starters that are the top ranked JRating horse from each race. Given
that 8 horses is the average field size for all races, a Data Window query
using a Quick Index File will run approximately 8 times faster than the same
query run using the PlayList file from which the Quick Index File was
extracted.
To create a
Quick Index File, follow these steps:
1. Start the
Quick Index File Extract Tool by clicking the Quick
Index File Extract button found on the JCapper Main Module or the QX button found on the Data Window.
2. Select a
Factor from
the Factors Drop Down.
3. Select Rank from the Rank Drop Down.
4. Click the
Folder Icon.
Use the Folder Nav Tool to browse folders on your system and navigate to the
folder where your source PlayList file is located
5. Click the
Build Index button. Select your source PlayList file and open it.
That's it. The Quick Index File
Extract Tool will create a Quick Index File containing only those starters
fitting the parameters for factor and/or rank that you selected.
Notes on the
Quick Index File Extract Tool
Folder Icon - The Folder Icon is used
throughout JCapper to allow directory or folder browsing. Clicking the Folder
Icon will open the Folder Nav Tool. Double Click an individual folder to select
it. Each time a new folder is selected, the folder name will appear on the
Build Index button and on the blue title bar at the top of the module's screen.
Close the Folder Nav Tool at any time by clicking the module screen outside of
the Folder Nav Tool's border.
+Create New
Index -
This is the default setting. When +Create
New Index is selected, the Quick Index File Extract Tool will create a new quick
index file, overwriting any existing quick index file in the same folder having
the same file name. File names are based on the factor selected from the
factors drop down.
-Add to
Existing Index
- When -Add to Existing Index is
selected, instead of creating a new quick index file, the Quick Index File
Extract Tool will append to any
existing quick index file in the pointed to folder. This makes it possible for
the user to create quick index files spanning databases located in multiple
folders.
Quick Index
Files Spanning Multiple Databases -
It is possible for the user to create quick index files spanning
databases located in multiple folders. For example, users who maintain one
folder and database for each quarter during a calendar year might find it
desirable to create a single JRating quick index file containing information
extracted from all four databases. Data Window query speed on the JRating quick
index file will be markedly faster than query speed using quarterly PlayList
files.
To create quick index files spanning databases from multiple folders,
use the following strategy: First, point the Quick Index File Extract Tool to
Folder A and create a new Quick Index File in folder A. Then, copy your Quick
Index File from Folder A to Folder B. Then, point the Quick Index Extract Tool
to Folder B, and select - +Add to Existing Index and create the
same type of index for Folder B that you just copied from Folder A. Instead of
creating a new file, the Quick Index File Extract Tool will append Folder B's information to the
Quick Index File that you copied in from Folder A. The resulting Quick Index
File in Folder B now contains data from both Folder A and Folder B. You can now
copy Folder B's Quick Index File to Folder C and repeat the process as needed...
Common Dialog Control - The Common Dialog Control
used throughout JCapper for selecting and opening files has some functionality
that goes beyond what you see at first glance. The Dialog Control also gives
you access to many of the same libraries available to Windows Explorer. Because
of this, when you open a Common Dialog Control and point to a folder, you can
also perform many of the same functions that you could if you were using
Windows Explorer to point to the same folder. You can right click on any file,
and copy the file to the Clipboard by selecting copy. You can also delete any
file. You can right click in the white space between file names, allowing you
to perform any number of the same things available to you in Windows Explorer
such as creating/renaming folders and pasting files to the current folder. The
Common Dialog Control also provides built in navigation elements that allow you
to browse to other drives and folders.
-end section on Quick Index
File Extract Tool -