
|
JCapper Message Board General Discussion
|
| Home |
Register
Log In |
| By | build 198 | |
| jeff 9/28/2016 3:58:17 PM | Progress Update For about the past three years I've been quietly working on a major program upgrade. Right now I'm at the point where about 99% of the work for everything I set out to do is finished and unit tested. I am going to deliver the new program version of Platinum first. A new version of Silver will follow about 7-10 days after I publish the new version of Platinum. Last night (09-27-2016) I compiled a new Platinum Download package and uploaded it to the server. EDIT: 09-28-2016 1:45 pm pacific time: I just now compiled a new download package dated 09-28-2016 and uploaded it to the server. If you install get the 09-28-2016 download package (not the one dated 09-27-2016.) -jp . See the following threads (some are in the private area of the board so you'll need to be logged in in order to read them) for some hints about what's in the new Platinum program version: Wish List - Parsing Rider Changes from the XML: http://www.jcapper.com/messageboard/TopicReader.asp?topic=2012&forum=Private Negative Weights - UPR Tools Expression Bulder - Logistic Regression Example: http://www.jcapper.com/messageboard/TopicReader.asp?topic=1987&forum=Private Situational Queries/Bankroll Detail Report: http://www.jcapper.com/messageboard/TopicReader.asp?topic=1907&forum=Private I've also updated the following help docs. They now cover features found in the new program version: Prob Expressions Help Doc updated: http://www.jcapper.com/helpDocs/ProbExpressions.html Scratch BOT Help Doc updated: http://www.jcapper.com/helpDocs/JCapper_ScratchBot.htm I've unit tested everything in the new version myself - and about 99% of it appears to be working as designed at my end. The next step before formally publishing is to email out download links to a handful of invitees who've indicated a desire to beta test the new version. This will happen sometime today. If you are a current Platinum HDW data subscriber and you'd like to beta test the new version shoot me an email. From there, in a few days, provided no one in the beta testing group reports anything amiss, I'll formally publish the new version. -jp . ~Edited by: jeff on: 9/28/2016 at: 12:29:36 PM~ ~Edited by: jeff on: 9/28/2016 at: 3:58:17 PM~
| |
| jeff 9/29/2016 3:32:08 PM | Progress update - Thurs morning 09-29-2016: Build 198 ver 2.0 program downloads page updated with a Scratch BOT ONLY special download package that contains a bug fix for a bug discovered by the beta testing group. Also updated the FULL Build 198 ver 2.0 download package to contain the revised Scratch BOT module mentioned above. If you installed the (original) 09-27-2016 download package - get current by installing the FULL 09-29-2016 download package. If you downloaded the FULL 09-28-2016 download package from yesterday - you can get current by installing the Scratch BOT ONLY 09-29-2016 special download package. Getting much closer (to being able to formally publish) now... -jp .
| |
| jeff 10/6/2016 11:21:22 AM | Progress update: Many in the beta testing group are reporting that the new J2 StarterHistory import routine is too slow. I'm back in San Diego as I type this - and yesterday morning I took a long look at this. The routine actually does run to completion under all versions of Windows -- But it's especially SLOW on older laptops that have been upgraded to Windows 10. (On some machines so slow that it doesn't appear to run at all.) The cause appears to be lack of memory on those older machines combined with the new J2 import routine being more complex (and therefore more memory intensive) than the J2 import routine found in previous (build 193 and earlier) versions of JCapper. The J2 import routine shipped with previous versions of JCapper (build 193 and earlier) was simpler/faster/less memory intensive because there was an underlying assumption that the newer version of any given table was just about always going to have the same number of data fields as older versions of the same table. The new J2 import routine shipped with build 198 ver 2.0 is more complex and uses more memory than the original because that same assumption doesn't exist any more. In build 198 I've added new data fields to many of the newer version tables. The new J2 import routine actually synchs up all of the data fields in each table by data field name -- which enables the routine to export data out of an older table with fewer fields to newer tables that contain newly added data fields -- or vice versa -- and even handles cases where the table structure between two tables is markedly different -- which gives me some flexibility in publishing new table content. That said -- looking at the build 198 J2 StarterHistory import routine specifically -- when I initially wrote it I tested it by running it on a brand new FAST laptop with a BIG ssd hard drive. The build 198 J2 StarterHistory import routine tested out as a little slower vs. the original routine run on (then new) machines from 2012-2013... BUT -- because I was testing the new routine on a new/fast machine with a big ssd hard drive -- it tested out as acceptable. Yesterday morning I ran the same J2 import routine (that those of you in the beta testing group tried to run a few days ago) on a 3 yr old laptop that doesn't have an ssd hard drive -- and can clearly see that it's horribly slow -- to the point where the right thing to do is scrap the routine (and start over.) That said, I spent a several hrs yesterday creating a brand new J2 StarterHistory parse routine for build 198 -- with an eye towards optimizing read and write speed. I'm testing it right now on a 3 yr old laptop that doesn't have an ssd hard drive -- and although it tests out a little slower than the routine shipped in build 193 from 2013 -- it's MUCH MUCH faster than the parse routine distributed to those of you in the beta testing group a few days ago. I'm going to continue with testing -- and try to make a few further incremental improvements. As soon as the new J2 Import routine tests out as acceptable on 3-4 year old laptops -- I plan on publishing the Platinum Build 198 program update to HDW data customers as well as those Brisnet customers who have (recently) paid or prepaid for program updates. I fully expect that to happen sometime within the next 48 hrs. -jp .
| |
| jeff 10/8/2016 11:24:49 AM | Progress Update: Most in the beta testing group are reporting that they CAN run the revised J2 StarterHistory table import routine mentioned in my previous post from10-06-2016 (above.) But a few are reporting the revised routine is too slow (on their older machines) to be workable for them. Yesterday I had 3 members of the beta testing group use the free file transfer function at WeTransfer.com to send me their (older version) JCapper2.mdb files... From there I ran the J2 StarterHistory table import routine at my end -- importing data out of their older version JCapper2.mdb files into a current version build 198 v2 JCapper2.mdb file... And from there used the free file transfer function at WeTransfer.com to send (new) current version build 198 v2 JCapper2.mdb files (with their older data intact) back to them. Each one took about 40 minutes -- so that was about 2 hrs out of my day. Obviously, I can't do that for everybody. Guys - I'm going to spend a bit more time on the J2 StarterHistory table import routine - and figure out a way to make it faster/eliminate its data bottleneck(s) - before I formally publish build 198. Thanks in advance for your patience. -jp .
| |
| jeff 10/10/2016 10:37:55 AM | Progress Update: Finally getting somewhere with the rewrite to the J2 StarterHistory Table Import Routine... --Screenshot: 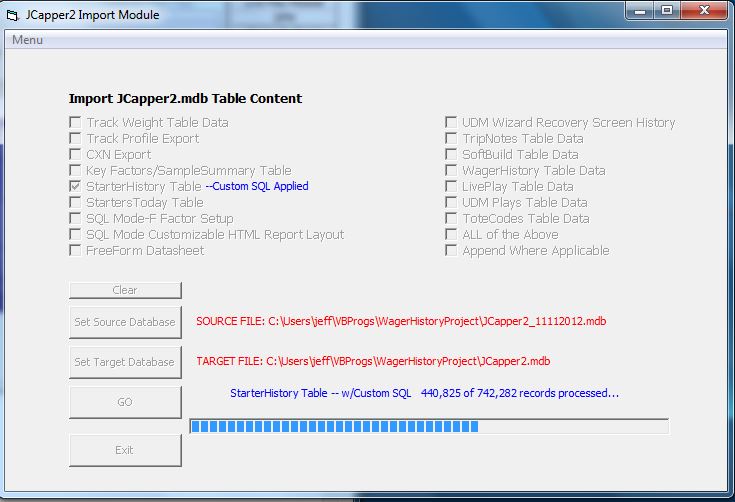 The above screenshot of the J2 Import Module was taken while a StarterHistory table import was underway. FYI, the StarterHistory table in the source file has about 23 months or approx 93k races or approx 742k records of StarterHistory table data in it. The new routine really isn't all that much faster than the previous routine I published last week. BUT -- It does a much better job of behaving in Windows. The new routine in the above screenshot does the following with each 175 records processed: 1. Updates the face of the module to display both the number of records processed and the total records to be processed in the import. 2. Checks in with Windows - basically telling Windows that the program window where the J2 Import Module is running is currently active. As a result, so far in my testing: The J2 Import Module doesn't hang - and even on older machines - never displays the text "Not Responding" (without the quotes) on its title bar - and (again so far in my testing) -- always runs to completion. I'm going to continue hammering away at that this - but did want to let you guys know that I AM getting somewhere. -jp .
| |
| chrisl 10/12/2016 11:16:32 AM | No response from file build is killing me ~Edited by: chrisl on: 10/12/2016 at: 11:16:32 AM~
| |
| jeff 10/12/2016 4:27:25 PM | Chris, there's a LOT of places in JCapper where implementing the same technology can will go a long way towards making the user experience better. The following areas are (now) on my list: • Build Database Routines • Calc Races • JCP and XRD file build routines • Data Window Queries • Data Window Exports -jp .
| |
| jeff 10/12/2016 10:28:23 PM | Progress Update: • Link to the updated Scratch BOT Help Doc: http://www.jcapper.com/helpDocs/JCapper_ScratchBot.htm The help doc now contains a section that covers getting Scratch BOT to process Rider Changes parsed from the XML. Here's a cut and paste of the Prerequisites List in that section: --quote: "Prerequisites List for seamless parsing of rider changes from the XML:--end quote • Screenshot of the new Enhanced Setttings Module: http://www.jcapper.com/messageboard/avatars/EnhancedSettingsForRiderChanges.jpg This screenshot shows the Enhanced Settings Module found in JCapper Build 198. Note that the settings from the Prerequisites List (above) needed to make Scratch BOT process rider changes from the XML are shown highlighted in yellow. • Screenshot of XML for KEE R2 horse #1 on 10-12-2016: http://www.jcapper.com/messageboard/avatars/KEE10122016R2_XML.jpg This screenshot shows the XML for KEE R2 horse #1 on 10-12-2016. Note that the replacement rider name in the XML is "Florent Geroux" (without the quotes.) With all of the items in the Prerequisites List (from the Scratch BOT Help Doc) met - Upon parsing the replacement rider name "Florent Geroux" (without the quotes) from the XML - the interface performs the following: 1. It strips punctuation characters from the name parsed from the XML - and then breaks the name up into parts - first/middle/suffix, etc. 2. It then assembles the parts into a name that matches the same format as HDW rider names inserted into .JCP files. 3. It searches the Name2 field in the CXNNames table looking for a match between the entries in the table and the reformatted name created in step 2 above. 4. If a Name2 match is found, it checks the entry in the table (True or False) for resolved name status. If resolved name status is True, the interface processes a rider change using the value of the Name1 field from the resolved name entry where the match was found. Processing the rider name involves inserting the replacement rider name into the .JCP file as well as stats for the replacement rider provided the replacement has at least one mount listed in the .JCP file for today's card. If the replacement rider has zero mounts in the .JCP file that day the interface is programmed to insert the replacement rider name into the .JCP file only. (In the interest of processing speed the interface does not go looking in other .JCP files trying to find replacement rider stats.) If resolved name status is False, the interface is programmed to stop there and move on to the next name parsed from the XML. About that... An entry in the CXNNames table must contain a verified entry in the Name1 field before achieving resolved name status - and the interface is programmed to process rider changes ONLY when resolved name status exists. (Think about it. You don't want the interface to guess at rider names when it overwrites a .JCP file.) 5. If a Name2 match is not found - the interface is programmed to kick things off for next time by creating a new entry in the CXNNames table - writing the formatted name from step 2 above to the Name2 field. • Screenshot of CXNNames Table Entry: http://www.jcapper.com/messageboard/avatars/KEE10122016R2_CXNNamesTableEntry.jpg This screenshot shows the CXNNames table entry for "GEROUX FLORENT" (without the quotes) in the CXNNames Table Interface. Note that the entry is a resolved name because: 1. The text in the Name1 field matches the rider name (with punctuation characters removed) in the .JCP file. 2. The text in the Name2 field matches the rider name as it appears in the XML. 3. The interface verified items 1 and 2 (immediately above) and then activated the entry as a resolved name by auto inserting a value of -1 (or True) into the Active field. From this point forward - whenever "Florent Geroux" (without the quotes) is parsed from the XML as a replacement rider name - the replacement rider name listed in the Name1 field GEROUX FLORENT" (without the quotes) will be processed as the replacement rider name. • Screenshot of Changes Table Report rider change for KEE R2 horse #1 on 10-12-2016: http://www.jcapper.com/messageboard/avatars/KEE10122016R2_ChangesTableReport.jpg • Screenshot showing the (new) summary section at the top of the Changes Table Report for 10-12-2016: http://www.jcapper.com/messageboard/avatars/ChangesTableReport2_10122016.jpg.jpg The first screenshot shows a highlighted row on the Changes Table Report displaying a rider change for KEE R2 horse #1 on 10-12-2016. The second screenshot shows the summary section at the top of the report. Note that the (now 99.9% close to finished) report contains embedded javascript that highlights individual rows as you click them. The report now also contains a header that displays with each 15 rows (making it easier to read.) The report now contains a formatted summary section at the top making it easy to know when new changes have been picked up from the XML. Finally, the report now contains a post time field - making it easy to know when new changes picked up from the XML are for races about to go off. FYI, getting post times to display on the report requires the following: 1. You need to install a current version JCapper.mdb file. The Changes table in the latest JCapper.mdb file now contains a posttime field. 2. You need to parse the XML after running a SQL Calc races for the folder you are parsing. (When you run a SQL Calc Races - one of the things that happens under the hood is that the Main Module writes date, track, race, surface, dist, posttime, and posttimetype to the RaceHeadingsToday table. This in turn, enables disaplay of UDM Plays in the SQL UDM Plays Module -- and yes -- display of post time in the new post time field on the Changes Table report. Note that if you run a changes table report before running a Calc Races for a folder where you have loaded .JCP files into the program in the DFM Card Laoder -- the RaceHeadings Today table won't yet contain any entries for the card files in that folder - and the post time field on the Changes Table report will be blank. (But as soon as you run a Calc Races for that folder - the next time you parse changes from the XML and run a Changes Table Report - your Changes Table Report will then display post time.) Latest Program Version FYI, I updated the build 198 download package earlier today at about 12:00 noon pacific time. The latest download contains updated .exe files for the JCapper Main Module, Scratch BOT, and the JCapper2 Import Module that I posted about a couple of days ago. The new Main Module contains bug fixes for all remaining issues pointed out to me by the beta testing group to date. (Many thanks. Multiple pairs of eyes are so much better than one.) The new Scratch BOT should get you everything shown in the screenshots above. And the new J2 Import Module behaves much better than the original in Windows when your machine runs out of memory and starts writing to the swap or paging file. I recommend everybody in the beta testing group -- as well as those of you who weren't originally part of the beta testing group but who I emailed download links out to -- go ahead and get the latest version at this time. -jp . ~Edited by: jeff on: 10/12/2016 at: 10:28:23 PM~
| |
| chrisl 10/12/2016 5:12:14 PM | My file build does not and has not worked, since I downloaded the update you sent over a month ago.
| |
| jeff 10/12/2016 10:19:49 PM | I had absolutely no idea Chris. Please call or email. I'll do my best to get things straightened out. -jp .
| |
| jeff 10/14/2016 2:05:31 PM | --quote: "No response from file build is killing me"--end quote --quote: "Chris, there's a LOT of places in JCapper where implementing the same technology can will go a long way towards making the user experience better.--end quote Progress Update 10-14-2016: Working all day yesterday and this morning - I have taken the same technology from my post (above dated 10/10/2016 and timestamped 10:37:55 AM) about getting the JCapper2 Import Module to be better behaved in Windows - and have now implemented it into the following areas of JCapper Platinum Build 198 ver 2.0:
Earlier today I compiled a new JCapper Build 198 ver 2.0 program download package. The new program download package is dated 10-14-2016 and includes the above changes. -jp .
| |
| jeff 10/15/2016 12:30:17 PM | Progress Update 10-15-2016: Earlier today I implemented the same technology from yesterday's post (above) into the .XRD File Build routine area of the HDW File Mgr. During an .XRD File Build Routine - a brief description of each operation is now displayed just to the right of the current filename being processed. Also during an .XRD File Build Routine - the module now continuously updates Windows with information about its current state. The end result is a drastic reduction in total elapsed time where Windows buts in and displays "Not Responding" on the module's title bar. If you are in the beta testing group: Earlier today I compiled a new JCapper Platinum Build 198 ver 2.0 program download package. The new program download package is dated 10-15-2016 and includes the above changes. I recommend everyone in the beta testing group get the latest program version at this time. What about the rest of you? A number of you outside the beta testing group have emailed to ask "When are you going to publish this thing?" The past 48 hrs have been kind of quiet. A few "How do I do that?" emails from the beta testing group -- but no new "this looks funny" or "got an error" emails. I'm going to continue stress testing different areas of the program over the next day or so. However, unless anything unforeseen pops up... Right now the new version is looking pretty stable and I feel pretty confident about making the following announcement: I'm going to publish JCapper Platinum Build 198 ver 2.0 as a formal program upgrade this coming Monday night - October 17, 2016. -jp .
| |
| jeff 10/18/2016 4:42:19 PM | Announcement 10-18-2016: As of right now about 2:30 pm pacific on Tuesday 10-18-2016 -- I'm officially publishing JCapper Platinum Build 198 ver 2.0 as a new program update. If you are a registered Platinum program owner -- and are a current HDW subscriber -- or alternately if you recently paid or prepaid the renewal update fee: Sometime within the next few hrs -- when you log into the JCapper Message Board - your program downloads page should look like the one in this screenshot: http://www.jcapper.com/messageboard/avatars/dloadpageb198.jpg The new link will take you to the JCapper Platinum Build 198 ver 2.0 program downloads page. There you will find a download link and complete install instructions. Hint: Read the instructions first -- and pay particular attention to the following: • The new version comes with brand new .mdb files -- and you need to install both before you can use (many/most) of the new features. • If you are running Windows 8 or Windows 10: You need to manually create a new desktop shortcut naming the program download package file as the shortcut's target. From there, when you run the extractor -- right click the new Shortcut -- and select RUN AS ADMINISTRATOR. It's the easist way to get true admin rights under Windows 8 or Windows 10. Be patient if you don't see the new link right away. I have to work through the registered program owner list manually - and add permissions for the new program downloads page one customer profile at a time. It follows that some of you are going to see the new link almost immediately, some of you are going to see it soon, and some of you aren't going to see it until I'm nearly done. Please bear with me (there's no other way.) -jp .
| |
| jeff 11/3/2016 7:41:23 PM | Progress Update 11-03-2016: 1. A new JCapper program download package (dated 11-03-2016) is now available on the JCapper Build 198 program downloads page. Hint: Install this latest program update first - before diving in to the new features described in the new help doc mentioned below. 2. The new JCX File Exports Module Help Doc (last updated 11-03-2016) is now up on the Help Docs Page at JCapper.com. Here's a direct link: http://www.jcapper.com/helpDocs/JCXFileExportModule.html The Help Doc itself is still being written. I'd guess it's about 85% complete as I type this. (Far enough along that I now feel comfortable posting about it.) After installing the latest program update - I'm guessing most of you won't have too much trouble getting to the point where you can: 1. Export vertical exotics data to a copy of the new JCapperSDK. mdb file. 2. Connect the SQL Data Window to a copy of the JCapperSDK. mdb file that contains exported vertical exotics data. 3. Use the SQL Data Window to query vertical exotics data in the connected to JCapperSDK. mdb file. -and- 4. See vertical exotics data in the Data Window. --Link to a screenshot from the Help Doc - here: -jp .
| |
| jeff 11/15/2016 4:14:26 PM | Progress Update: 11-15-2016 Over the past several days (as free time permits) I've been quietly working away at getting Parsing of Rider Names from the XML enabled for Brisnet .mcp and .drf files. I'm wondering if there are still any "grandfathered in" .TSN data plan subscribers out there - who are downloading .MCP files for all track codes. If so - could one of you shoot me an email at: jeff @ jcapper . com (remove the blank spaces first) I'm looking for to obtain a limited number of .mcp files for unit testing and debugging purposes. I'm specifically interested in files for two character track codes (AP, GP, GG, WO, etc.) I'm also looking to pick up least one sample .mcp file for track code FPK (Fairmont Park.) I figure asking for help might be easier than spending time hunting and pecking for files on the Brisnet archive server. -jp .
| |
| jeff 11/21/2016 12:36:59 PM | Progress Update: 11-21-2016 Item #1. I have a working version of Scratch BOT at my end that parses rider changes from the XML - that is now compatible with both HDW and Brisnet data files. The parse routine remains the same (almost 100% seamless) if you are an HDW data customer. That is because almost all of the names HDW inserts into their data files are the same as the rider names found in the XML. The same parse routine works with Brisnet data too - but it requires that the user create resolved name entries in the CXNNames table for each individual rider at those track codes where he or she is playing. The reason for this is because - unlike HDW names, where there are only a handful of differences between the names in the data files and the names in the XML - almost all of the rider names in Brisnet data files are different than the name in the XML for that same rider. If you are using Brisnet data and are playing one or two track codes this isn't a big deal. Once you create resolved name entries for the riders at the track codes where you are playing - you should be good to go. But if you are using Brisnet data and are playing every available track code - creating resolved name entries is still doable - but the effort could be a bit overwhelming. Item #2. In the version of Scratch BOT (mentioned above) - I have modified the Changes Table Report so that it now displays (any) unresolved rider names (needing attention) in bright red font - so as to make them stick out. Item #3 The version of Scratch BOT (mentioned above) also now contains a brand new Wizard Style Interface - for the specific purpose of enabling the user to quickly create resolved rider name entries in the CXNNames Table - on an as needed basis per rider names that (now) stick out on the new Changes Table Report. Item #4 The version of Scratch BOT (mentioned above) also now contains a brand new Wizard Style Interface - for the specific purpose of enabling the user to quickly (with just a few mouse clicks) perform a Manual Rider Change. Link to screenshot here: "http://www.JCapper.com/MessageBoard/Avatars/ManualRiderChange01.jpg I'm going to continue testing the new version of Scratch Bot at my end - and provided all goes well - I plan to publish it as part of the next program update - most likely just after the Thanksgiving holiday. So right now as I type this - it very much looks like parsing rider changes from the XML is soon going to be enabled in Build 198 for Brisnet data customers too. -jp .
|
| Reply |
|
Copyright © 2018 JCapper Software back to the JCapper Message Board www.JCapper.com |